
Your application works perfectly with 1,000 users. Then 100,000 show up on launch day and everything breaks.
That is a scalability problem. And it kills products faster than bad design or weak marketing ever could.
Software scalability is what separates systems that grow with demand from systems that collapse under it. Netflix handles over 200 million subscribers across multiple regions because scalability was built into every layer of their architecture. Most apps never reach that scale, but the principles apply at every stage.
This article covers what software scalability actually means, the difference between horizontal and vertical scaling, the architecture patterns that support elastic growth, key metrics for measuring system capacity, and real strategies used by companies like Airbnb and AWS to handle unpredictable workloads.
What is Software Scalability
Software scalability is the capacity of a system to handle growing workloads, more concurrent users, and larger data volumes without losing performance or reliability.
It covers both adding resources to existing servers and distributing work across multiple machines.
A scalable software system keeps response times stable whether 100 people or 10 million people are using it at the same time.
Scalability is a quality attribute defined alongside maintainability, software reliability, and portability under the ISO 25010 software quality model.
It is not just about handling more traffic. Scalability also means the system can scale down when demand drops, keeping infrastructure costs reasonable.
Think of it as the elasticity of your compute resources. Netflix runs hundreds of microservices that scale independently per region. Airbnb started on a single monolith and hit a wall before rearchitecting for horizontal distribution.
Scalability decisions made early in the software development process affect everything down the line, from database design to deployment strategy to long-term cost.
Why Does Software Scalability Matter for Applications?

A system that can’t scale fails at the worst possible time. Traffic spikes, product launches, seasonal demand, viral content. These are the moments your application needs to perform, and they’re exactly when a non-scalable system crashes.
Amazon reported in 2012 that every 100 milliseconds of added latency cost them 1% in sales. Google found that an extra 0.5 seconds in page load time caused a 20% drop in traffic.
The numbers still hold true at scale.
Poor scalability leads to:
- Server crashes during peak concurrent user requests
- Increased error rates and timeout failures under load
- Revenue loss from degraded user experience
- Higher infrastructure costs from over-provisioning to compensate
- Slower feature delivery because the team spends time fixing bottlenecks
Scalability is also tightly linked to high availability. A system that can distribute workload across multiple nodes stays online even if one server goes down.
For web apps handling thousands of API calls per second, or mobile applications with unpredictable user bases, building for scalability from the start is not optional. It is a non-functional requirement that determines whether your product survives growth or collapses under it.
Plenty of failed startups had solid products that simply couldn’t handle user demand when it arrived.
What Are the Types of Software Scalability?
| Scalability Type | Core Definition & Methodology | Implementation Strategy | Primary Use Cases & Benefits |
|---|---|---|---|
| Horizontal Scalability (Scale-out Architecture) | Increases system capacity by adding more server instances or computing nodes to distribute workload across multiple machines. Load balancing mechanisms distribute requests among server clusters. | Deploy load balancers, implement distributed databases (MongoDB, Cassandra), use containerization (Docker, Kubernetes), and microservices architecture patterns. | Web applications: E-commerce platforms handling traffic spikes Cloud services: AWS Auto Scaling Groups Benefits: Cost-effective scaling, fault tolerance, geographic distribution |
| Vertical Scalability (Scale-up Architecture) | Enhances system performance by increasing hardware resources (CPU cores, RAM, storage capacity) within existing server infrastructure without architectural changes. | Upgrade CPU processors, increase memory allocation, enhance storage systems (SSD arrays), optimize database server configurations, and improve network bandwidth capacity. | Database systems: MySQL, PostgreSQL optimization Legacy applications: Monolithic enterprise software Benefits: Simple implementation, no code refactoring required, immediate performance gains |
| Functional Scalability (Feature-based Scaling) | Scales specific application features or modules independently based on demand patterns, allowing targeted resource allocation for high-usage functionalities while maintaining system efficiency. | Implement service-oriented architecture (SOA), deploy API gateways, create feature-specific microservices, and use event-driven architecture with message queuing systems. | SaaS platforms: Scaling user authentication separately from data processing Media streaming: Video encoding services independent scaling Benefits: Resource optimization, modular development, targeted performance improvements |
There are two primary approaches to scaling a system: vertical scaling and horizontal scaling. A third hybrid option, diagonal scaling, combines both.
Each comes with real trade-offs in cost, complexity, fault tolerance, and long-term growth potential. The right choice depends on your application architecture, traffic patterns, and budget.
What is Vertical Scaling (Scaling Up)?
Vertical scaling means adding more CPU, RAM, or storage to a single server. You keep the same machine and make it more powerful.
This approach works well for monolithic architectures and applications with predictable workloads. PostgreSQL databases, for instance, often benefit from vertical upgrades before sharding becomes necessary.
The setup is simpler. Your codebase stays as-is. No need for distributed state management or load balancing.
But there’s a hard ceiling. Every machine has a maximum threshold for RAM, processing power, and storage. You’ll hit it eventually.
Other downsides:
- Single point of failure, if that server goes down, everything goes down
- Upgrades often require downtime for the resize
- Cost grows non-linearly as you approach top-tier hardware
Vertical scaling buys you time. It does not buy you infinite growth.
What is Horizontal Scaling (Scaling Out)?
Horizontal scaling adds more machines to distribute the workload. Instead of one powerful server, you run many smaller ones behind a load balancer.
This is how Netflix, Google, and most large-scale platforms operate. Each service runs in its own container, managed by Kubernetes, and scales independently based on traffic.
The benefits are significant: fault tolerance (losing one node doesn’t kill the system), near-limitless growth potential, and better resource utilization across distributed infrastructure.
But it comes with complexity. You need to think about session persistence, data consistency across nodes, service discovery, and network latency between distributed components.
Applications need to be architected for this from the start. Stateless application design helps a lot. If your app stores session data on a single server, scaling out gets tricky fast.
Containerization and orchestration platforms like Kubernetes have made horizontal scaling far more accessible, but the architectural planning still falls on the team.
What is Diagonal Scaling?
Diagonal scaling starts with vertical upgrades and switches to horizontal distribution once hardware limits are reached.
It is a hybrid model suited for organizations with unpredictable demand. You get the simplicity of scaling up for normal operations, with the ability to scale out during spikes.
More expensive to operate and more complex to manage, but it covers both ends of the spectrum.
How Do Vertical and Horizontal Scaling Compare?
The horizontal vs vertical scaling decision shapes infrastructure cost, system resilience, and engineering effort for the life of your product.
Here is a direct comparison across the properties that matter most:
- Cost – Vertical is cheaper upfront but expensive at the top end. Horizontal spreads cost across commodity hardware.
- Complexity – Vertical requires almost no architectural change. Horizontal demands distributed system design, orchestration, and load balancing.
- Fault tolerance – Vertical has a single point of failure. Horizontal survives node failures without downtime.
- Downtime risk – Vertical scaling often requires server restarts. Horizontal adds nodes with zero downtime.
- Growth ceiling – Vertical hits hardware limits. Horizontal has no theoretical cap.
- Data management – Vertical keeps data on one machine (simpler). Horizontal needs sharding, replication, and consistency strategies.
- Best fit – Vertical works for predictable, moderate workloads. Horizontal fits high-growth, distributed systems.
Most production systems at companies like Airbnb and Netflix use both. Certain database servers scale vertically for heavy compute, while application services scale horizontally across regions.
A software architect typically evaluates traffic forecasts, tech stack constraints, and team expertise before recommending one approach or a combination of both.
What Software Architecture Patterns Support Scalability?

Architecture decisions made during the design phase determine how well a system can scale later. Some patterns support elastic growth naturally. Others make scaling painful, expensive, or nearly impossible without rewriting the whole thing.
How Do Microservices Improve Scalability?
A microservices architecture splits an application into small, independently deployable services, each responsible for a single function.
The biggest advantage for scalability: each service scales on its own. Your payment processing service might need 10 instances during checkout surges, while the user profile service stays at 2.
Kubernetes manages this through horizontal pod autoscalers. Services communicate over RESTful APIs or message queues like Apache Kafka, keeping them loosely coupled.
Netflix runs over 700 microservices. Each one can be updated, deployed, and scaled without touching the others. That level of independence is what makes microservices the default for high-scale back-end systems.
How Does a Monolithic Architecture Limit Scalability?
A monolith is a single, tightly coupled codebase where all components share the same process and resources. To scale any part, you scale everything.
This forces reliance on vertical scaling. And when that hits its ceiling, the only option is a painful migration to distributed services. Airbnb went through exactly this transition when their Ruby on Rails monolith couldn’t keep up.
For early-stage products, monoliths are fine and even faster to build. But they become a bottleneck as traffic and team size grow, which is why code refactoring toward service boundaries is a common step in the app lifecycle.
What Role Do Load Balancers Play in Scalability?
A load balancer distributes incoming traffic across multiple servers so no single machine gets overwhelmed.
It sits between the client and your server pool, routing requests using algorithms like round-robin, least connections, or IP hash. NGINX and HAProxy are the most common choices. Cloud providers offer managed options like AWS Elastic Load Balancer and Azure Load Balancer.
Load balancers also run health checks. If a node fails, traffic automatically reroutes to healthy instances, which is critical for fault tolerance in horizontally scaled systems.
How Does Database Sharding Help Scale Data?
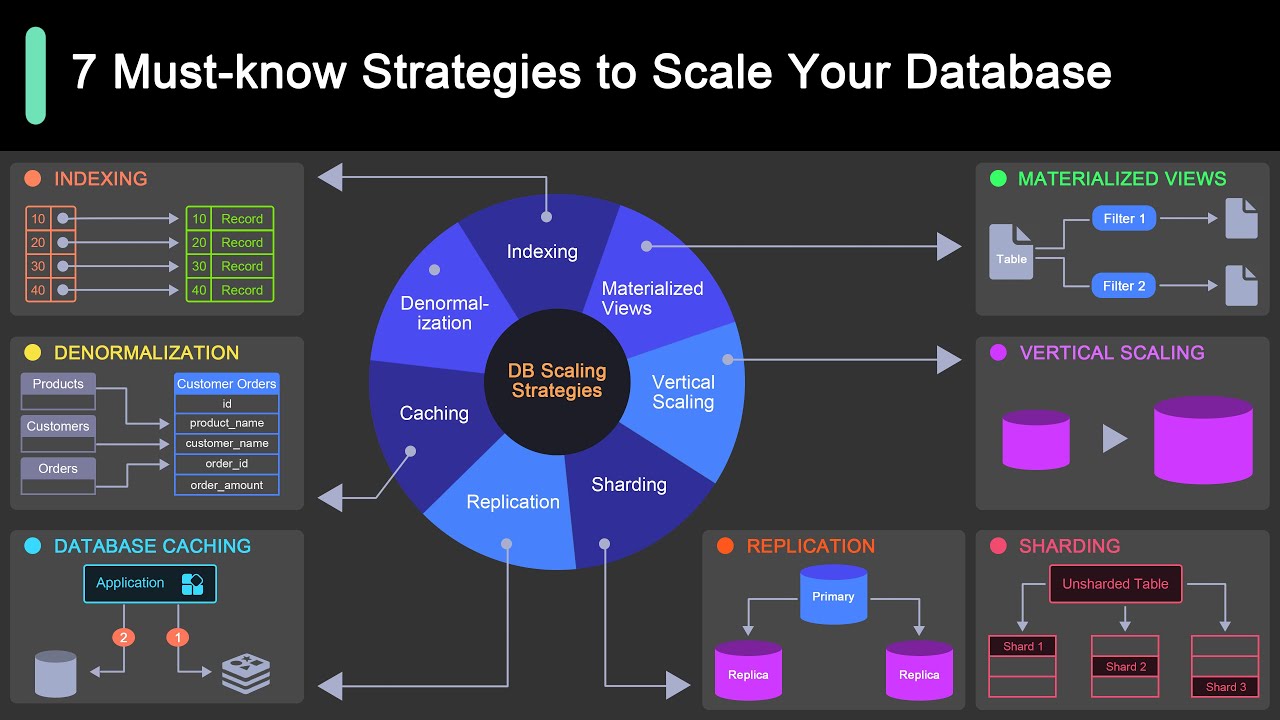
Database sharding splits a large database into smaller partitions (shards), each stored on a separate node. This is horizontal partitioning of data.
Apache Cassandra and MongoDB support sharding natively. It allows read and write operations to distribute across nodes, reducing bottlenecks as data volume grows.
The trade-off is consistency. The CAP theorem (formulated by Eric Brewer) states that a distributed system can only guarantee two of three properties: consistency, availability, and partition tolerance. Sharded databases typically sacrifice some consistency for availability.
Read replicas are a simpler alternative for read-heavy workloads, keeping the primary database for writes while copies serve read requests.
FAQ on What Is Software Scalability
What is the difference between scalability and performance?
Performance measures how fast a system responds under current load. Scalability measures how well that performance holds as load increases. A system can be fast at low traffic but completely fall apart when concurrent user requests spike during peak hours.
What are the two main types of software scalability?
Vertical scaling adds more CPU, RAM, or storage to a single server. Horizontal scaling adds more machines and distributes workload across them using a load balancer. Most production systems at companies like Netflix combine both approaches.
Why is scalability a non-functional requirement?
Scalability defines how a system behaves under stress, not what it does. It sits alongside reliability, security, and portability as a quality attribute in frameworks like ISO 25010. It is specified during requirements engineering.
How does cloud computing support scalability?
Cloud platforms like AWS, Google Cloud Platform, and Microsoft Azure offer auto-scaling groups that add or remove compute instances based on real-time demand. Serverless functions like AWS Lambda scale automatically to zero when idle, cutting infrastructure costs.
What role does Kubernetes play in scaling applications?
Kubernetes orchestrates containerized applications and scales them through Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA). It handles service discovery, load distribution, and node management across distributed clusters automatically.
Can a monolithic application be scaled?
Yes, but only vertically. A monolith runs as a single production process, so the entire application scales together. This hits hardware limits fast. Teams eventually migrate to microservices for independent, horizontal scaling per service.
What is database sharding and how does it relate to scalability?
Database sharding splits data across multiple nodes using horizontal partitioning. MongoDB and Apache Cassandra support this natively. It distributes read and write operations to prevent bottlenecks, though it introduces consistency trade-offs described by the CAP theorem.
How do you measure software scalability?
Key metrics include throughput, latency, response time under load, error rate, and CPU/memory utilization. Tools like JMeter, Gatling, and k6 simulate traffic to identify the point where performance degrades. Load testing should happen before every major release.
What is diagonal scaling?
Diagonal scaling is a hybrid model that starts with vertical resource upgrades and switches to horizontal distribution once hardware limits are reached. It suits organizations with unpredictable demand patterns that need both simplicity and elastic compute capacity.
When should you plan for scalability in the development process?
From the start. Architecture decisions made during software modeling and system design directly affect scaling ability later. Retrofitting scalability into a tightly coupled system is expensive and often requires a full rebuild.
Conclusion
Software scalability is not something you bolt on after launch. It is an architectural decision that shapes your system’s capacity to handle growing workloads, more concurrent users, and larger data volumes over time.
Whether you choose vertical resource upgrades, horizontal distribution across clusters, or a diagonal hybrid depends on your traffic patterns, tech stack, and growth projections.
The patterns covered here, from microservices and container orchestration with Kubernetes to database sharding and load balancing with NGINX or HAProxy, are the same ones running behind Netflix, AWS, and Google Cloud Platform.
Start with clear feasibility analysis, measure throughput and latency under real load, and build scaling into your infrastructure from day one. Scaling later always costs more than scaling smart from the beginning.
- Best 5 AI Penetration Testing Tools for Web and Mobile Applications - August 2, 2026
- Android App Bundle vs APK - August 1, 2026
- PHP Cheat Sheet - July 31, 2026


