
Hadoop built the foundation of modern big data, but in 2025, most teams are moving on.
The batch-only MapReduce model, the operational weight of managing HDFS clusters, and the lack of native SQL support have pushed organizations toward faster, cloud-native solutions. Real-time processing is now the baseline expectation, not a bonus.
This guide covers the 10 best Hadoop alternatives available today, from open-source distributed computing frameworks like Apache Spark and Apache Flink to fully managed cloud platforms like Snowflake, Databricks, and Google BigQuery.
By the end, you will know which tool fits your workload, your team size, and your infrastructure budget, whether you need stream processing, petabyte-scale SQL analytics, or a full lakehouse migration path.
Hadoop Alternatives
Is Apache Spark a Good Hadoop Alternative for Real-Time Data Processing?
Apache Spark is a strong Hadoop alternative for real-time and iterative data processing. Its in-memory computing model delivers up to 100x faster performance than Hadoop MapReduce for memory-based operations, and its unified engine covers batch, streaming, ML, and graph workloads without extra tools.
What Is Apache Spark?
Apache Spark is an open-source distributed computing engine maintained by the Apache Software Foundation. Originally developed at UC Berkeley’s AMPLab and first released in 2010, Spark runs on Java, Scala, Python, and R.
Its current stable release is Spark 3.x. The license is Apache 2.0. It uses a DAG execution model instead of Hadoop’s two-stage MapReduce paradigm, which allows full workflow optimization before execution begins.
How Does Apache Spark Compare to Hadoop?
| Attribute | Hadoop | Apache Spark |
|---|---|---|
| Processing model | Batch only (MapReduce) | Batch, streaming, ML, graph |
| Data storage during jobs | Writes to disk after each step | Keeps data in RAM |
| Speed (iterative tasks) | Baseline | Up to 100× faster in-memory |
| Language support | Java primary | Java, Scala, Python, R |
| ML support | External (Mahout) | Built-in (MLlib) |
| License | Apache 2.0 | Apache 2.0 |
| Cluster RAM requirements | 8–16 GB per node | 64–128 GB per node (production) |
Spark’s DAG optimizer lets the engine collapse multiple operations into fewer passes, cutting I/O overhead that MapReduce cannot avoid. Its Resilient Distributed Dataset (RDD) abstraction and structured streaming API mean the same codebase can handle batch ETL and live stream processing without a separate pipeline tool.
Hadoop still wins on raw storage economics. A typical Hadoop node costs 30-40% less in hardware than a memory-optimized Spark node.
When Should You Choose Apache Spark Over Hadoop?
- Spark is the better choice when workloads are iterative, such as ML training loops that pass over the same data 10+ times.
- Spark is preferable for fraud detection, live dashboards, or IoT event processing where sub-second latency is required.
- Spark suits teams already using Python for data work, given its PySpark API and strong pandas interop.
- Spark is better when a single platform must handle batch ETL, real-time analytics, and machine learning without adding extra cluster tools.
What Are the Limitations of Apache Spark Compared to Hadoop?
- Memory cost: Production Spark clusters require 64-128 GB RAM per node, making hardware costs significantly higher than Hadoop’s disk-based nodes.
- No native file system: Spark has no built-in distributed storage. It depends on HDFS, Amazon S3, or another external system, adding an architectural dependency.
- Spark’s default security settings are minimal. Kerberos, Ranger, and LDAP that Hadoop bundles natively require extra configuration in Spark.
Is Apache Spark Free and Open Source?
Spark is released under the Apache 2.0 License, which allows free commercial use, modification, and distribution without restriction.
Is Apache Flink a Good Hadoop Alternative for Streaming Pipelines?
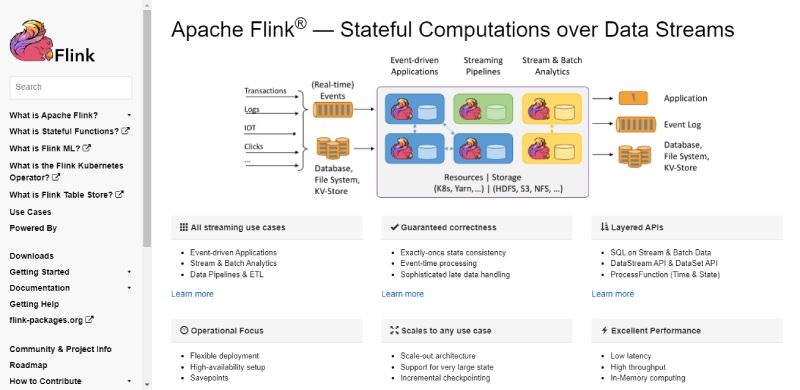
Apache Flink is a strong Hadoop alternative for event-driven and stateful stream processing. It delivers true per-record processing with sub-second latency, unlike Hadoop’s batch-only MapReduce model, making it the preferred choice for financial transactions, fraud detection, and real-time monitoring.
What Is Apache Flink?
Apache Flink is a distributed stream processing framework maintained by the Apache Software Foundation. It was initially released in May 2011 and is built as a streaming-first engine with batch processing added on top.
Major adopters include Netflix and Alibaba. Flink supports Java and Scala primarily and is licensed under Apache 2.0. Its stateful computation model lets pipelines maintain and update state in real time across unbounded data streams.
How Does Apache Flink Compare to Hadoop?
| Attribute | Hadoop | Apache Flink |
|---|---|---|
| Processing model | Batch (MapReduce) | Stream-first, batch supported |
| Latency | High (disk I/O bound) | Sub-second (per-record) |
| State management | None built-in | Native, fault-tolerant state |
| Time semantics | Processing time only | Event time, processing time, ingestion time |
| Ecosystem maturity | Very mature | Growing, lags Spark |
| License | Apache 2.0 | Apache 2.0 |
Flink’s event-time windowing handles out-of-order and late-arriving data precisely, which is a gap Hadoop cannot fill at all. Where Spark Streaming uses micro-batching to simulate real-time behavior, Flink processes each record as it arrives. That distinction matters in use cases like credit card fraud detection where even a 5-second delay is too long.
When Should You Choose Apache Flink Over Hadoop?
- Flink is the better choice when the pipeline processes continuous, unbounded data streams such as clickstreams or sensor feeds.
- Flink is preferable when your application needs complex event processing (CEP) across time windows with late-data correction.
- Flink suits teams running event-driven microservices that need per-record processing guarantees rather than batch outputs.
What Are the Limitations of Apache Flink Compared to Hadoop?
- Smaller ecosystem: Flink’s community and library support lags behind both Hadoop and Spark, particularly for Python and ML tooling.
- Batch processing performance in Flink is efficient but does not consistently match Spark’s optimized throughput for very large static datasets.
- Operational complexity is high. Flink requires careful state backend configuration (RocksDB or heap), checkpoint tuning, and resource management that Hadoop’s stable MapReduce model avoids.
Is Google BigQuery a Good Hadoop Alternative for SQL Analytics at Scale?
Google BigQuery is a strong Hadoop alternative for petabyte-scale SQL analytics. Its serverless architecture removes all cluster management overhead, queries terabytes in seconds, and runs entirely on Google Cloud without requiring HDFS, YARN, or MapReduce configuration.
What Is Google BigQuery?

Google BigQuery is a fully managed, serverless cloud data warehouse offered by Google Cloud Platform. It stores data in a columnar format using Google’s Colossus distributed file system underneath.
BigQuery supports standard SQL, integrates natively with Google Cloud services, and scales automatically with no cluster provisioning. G2 rates BigQuery at 4.5/5 with over 1,000 reviews. It holds a 13.48% market share in the cloud data warehousing category.
How Does Google BigQuery Compare to Hadoop?
| Attribute | Hadoop | Google BigQuery |
|---|---|---|
| Architecture | On-premise cluster (HDFS + YARN) | Serverless, fully managed SaaS |
| Query language | HiveQL (limited SQL) | Standard SQL |
| Scaling | Manual cluster expansion | Automatic, serverless |
| Setup overhead | High (cluster configuration, YARN tuning) | Near zero |
| Real-time processing | Not supported natively | Streaming inserts supported |
| Cloud dependency | Cloud-agnostic (self-managed) | Google Cloud only |
| License / pricing | Open source, infrastructure cost | Pay-per-query or slot commitment |
BigQuery’s columnar storage and Dremel query engine let it scan and aggregate petabyte datasets without the disk I/O bottlenecks that slow Hadoop MapReduce jobs. Teams that previously ran overnight Hadoop batch jobs often see the same queries complete in minutes on BigQuery. One CTO at a data platform company reduced nightly batch costs by 10x after switching from Hadoop to BigQuery flex slots.
When Should You Choose Google BigQuery Over Hadoop?
- BigQuery is the better choice when the team lacks dedicated infrastructure or cluster management expertise.
- BigQuery is preferable when workloads are primarily SQL-based analytics on structured or semi-structured data at petabyte scale.
- BigQuery suits organizations already running on Google Cloud that want native integrations with Looker, Vertex AI, and Google Sheets.
- BigQuery is a better fit when query frequency is unpredictable and pay-per-query pricing is more cost-effective than maintaining a permanently running Hadoop cluster.
What Are the Limitations of Google BigQuery Compared to Hadoop?
- Vendor lock-in: BigQuery runs exclusively on Google Cloud. Teams cannot self-host or move workloads to AWS or Azure without a full migration.
- BigQuery’s serverless model offers less architectural flexibility. Custom processing logic that Hadoop supports through MapReduce or Spark jobs requires workarounds or separate Cloud Dataflow pipelines.
- At high query volumes, slot-based pricing can become expensive compared to the fixed cost of a well-tuned on-premise Hadoop cluster.
Is Snowflake a Good Hadoop Alternative for Cloud Data Warehousing?
Snowflake is a strong Hadoop alternative for cloud-native data warehousing. It separates compute from storage, supports multi-cloud deployments across AWS, Azure, and GCP, and handles SQL queries on structured and semi-structured data without any cluster management. PeerSpot ranks Snowflake first among cloud data warehousing platforms with an average rating of 8.4.
What Is Snowflake?
Snowflake is a cloud-native SaaS data platform founded in 2012 and publicly traded since 2020. It runs on AWS, Azure, and Google Cloud and offers a unique architecture where storage, compute, and cloud services are fully separated.
Multi-cluster warehouses let Snowflake scale compute up or down per workload without touching storage. It supports standard SQL and semi-structured formats like JSON and Parquet natively.
How Does Snowflake Compare to Hadoop?
| Attribute | Hadoop | Snowflake |
|---|---|---|
| Architecture | Tightly coupled storage + compute | Separated compute and storage |
| Deployment | On-premise or self-managed cloud | Fully managed SaaS, multi-cloud |
| SQL support | HiveQL (limited) | Full ANSI SQL |
| Ease of use (G2) | Lower | Higher (Snowflake outperforms on G2) |
| Real-time ingestion | Not supported natively | Snowpipe for continuous loading |
| License | Apache 2.0 (open source) | Commercial SaaS |
Snowflake’s separation of storage and compute is the core architectural advantage. A Hadoop cluster must scale both dimensions together, which wastes resources when storage needs grow faster than compute or vice versa. A SaaS client serving analytics dashboards to 5,000 customers reportedly achieved 99.5% query SLA compliance on Snowflake using multi-cluster warehouses, something that would have required complex caching layers on other platforms.
When Should You Choose Snowflake Over Hadoop?
- Snowflake is the better choice when the organization wants zero cluster management and a fully managed cloud-based data platform.
- Snowflake is preferable for cross-cloud deployments where data must be queried from teams on AWS, Azure, and GCP simultaneously.
- Snowflake suits BI-heavy teams that need fast, concurrent SQL queries from many analysts without performance degradation.
What Are the Limitations of Snowflake Compared to Hadoop?
- Cost at scale: Snowflake’s credit-based pricing for compute can become expensive for always-on, high-concurrency workloads compared to a fixed-cost Hadoop cluster.
- Snowflake is not designed for custom, low-level data processing. Teams that need to run Python-based ML pipelines or graph processing must integrate external tools like Spark or Databricks.
Is Databricks a Good Hadoop Alternative for Lakehouse Architectures?
Databricks is a strong Hadoop alternative for unified lakehouse architectures. It combines Apache Spark-based processing with Delta Lake storage, supports ML pipelines natively, and set a data warehousing performance record on the 100 TB TPC-DS benchmark, reportedly 2.7x faster than Snowflake on that test.
What Is Databricks?

Databricks is a cloud-native data and AI platform founded by the original creators of Apache Spark. It runs on AWS, Azure, and Google Cloud and uses Delta Lake as its default open table format.
The platform unifies batch processing, real-time streaming, SQL analytics, and machine learning in a single collaborative notebook environment. Unity Catalog, added in 2023, provides centralized governance across Delta Lake and Apache Iceberg tables. The license is commercial SaaS, with Delta Lake open-sourced under Apache 2.0.
How Does Databricks Compare to Hadoop?
| Attribute | Hadoop | Databricks |
|---|---|---|
| Processing engine | MapReduce | Apache Spark (optimized) |
| ML support | None native | MLflow, MLlib, AutoML built-in |
| Storage format | HDFS | Delta Lake (ACID transactions) |
| Collaboration | None | Notebooks, workflows, dashboards |
| Deployment | Self-managed | Fully managed, multi-cloud |
| License | Apache 2.0 | Commercial SaaS |
Databricks’ Delta Lake adds ACID transactions and schema evolution to object storage, which traditional HDFS does not support. This makes the lakehouse pattern practical: raw data lands in cloud storage, and Delta handles the transactional guarantees that Hadoop’s flat file system lacks. Teams running an app lifecycle with continuous data ingestion benefit from this structure significantly.
When Should You Choose Databricks Over Hadoop?
- Databricks is the better choice when the team needs to run ML training pipelines alongside ETL jobs on the same platform without separate tooling.
- Databricks is preferable when data engineers and data scientists need to collaborate in shared notebooks with version-controlled workflows.
- Databricks suits organizations migrating from Hadoop that want to retain Spark compatibility while gaining managed infrastructure and Delta Lake governance.
What Are the Limitations of Databricks Compared to Hadoop?
- Commercial lock-in: Databricks is a paid platform. Cost scales with compute usage, and large production clusters can become expensive relative to self-managed Hadoop on commodity hardware.
- Databricks is primarily Spark-native. Teams using Hadoop ecosystem tools like HBase, Pig, or Oozie need to rewrite or replace those workloads during migration.
Is Amazon EMR a Good Hadoop Alternative for AWS-Native Big Data Workloads?
Amazon EMR is a practical Hadoop alternative for teams already on AWS. It manages Hadoop and Spark cluster provisioning, integrates natively with S3, Glue, and Redshift, and supports on-demand, reserved, and spot instance pricing to cut infrastructure costs significantly.
What Is Amazon EMR?
Amazon EMR (Elastic MapReduce) is a fully managed cloud big data platform offered by Amazon Web Services. It supports Apache Hadoop, Apache Spark, Apache Hive, Apache Flink, Presto, and other open-source frameworks on demand.
EMR uses EMRFS to treat Amazon S3 as HDFS, meaning data persists after cluster termination. PeerSpot rates EMR at 7.8 and ranks it 3rd in the Hadoop category with 20 reviews. The platform is commercial, priced per EC2 instance hour.
How Does Amazon EMR Compare to Hadoop?
| Attribute | Hadoop (self-managed) | Amazon EMR |
|---|---|---|
| Cluster management | Manual, requires ops team | Fully managed by Amazon Web Services |
| Storage | HDFS on local disks | EMRFS on Amazon S3 (persistent) |
| Framework support | Hadoop ecosystem only | Hadoop, Spark, Flink, Presto, Hive |
| Scaling | Manual node addition | Auto-scaling, spot instances |
| Cost model | Fixed hardware investment | Pay per EC2 hour, spot available |
| Cloud dependency | Cloud-agnostic | AWS only |
The key advantage of EMR over self-managed Hadoop is operational leverage. Teams that previously needed a dedicated platform engineering team to maintain Hadoop clusters can offload that to AWS and focus on the actual data processing logic. EMR’s spot instance support can cut cluster costs by 60-80% for fault-tolerant batch workloads.
When Should You Choose Amazon EMR Over Hadoop?
- EMR is the better choice when the organization already runs its software scalability strategy on AWS and wants native integrations with S3, IAM, and Glue.
- EMR is preferable for teams that want to run Hadoop workloads in the cloud without rewriting jobs, since EMR supports the full Hadoop ecosystem.
- EMR suits cost-sensitive batch workloads where ephemeral clusters on spot instances can process jobs overnight and terminate, avoiding idle cluster costs.
What Are the Limitations of Amazon EMR Compared to Hadoop?
- AWS lock-in: EMR is AWS-only. Teams with multi-cloud requirements or data sovereignty constraints that require on-premise deployment cannot use EMR.
- EMR clusters backed by HDFS (not S3) lose data on cluster termination. Workloads must be architected around EMRFS/S3 to ensure durability, adding design overhead.
Is Apache Storm a Good Hadoop Alternative for Complex Event Processing?
Apache Storm is a specialized Hadoop alternative for continuous stream processing and complex event processing. It processes data event-by-event without discrete batch boundaries, making it well-suited for real-time alerting and CEP workloads that Hadoop’s MapReduce cannot handle.
What Is Apache Storm?
Apache Storm is an open-source distributed real-time computation system maintained by the Apache Software Foundation. It was originally created by BackType and acquired by Twitter before being open-sourced in 2011.
Storm runs as a continuously executing topology, not a batch job. It uses Apache ZooKeeper for coordination and does not require HDFS or YARN. The license is Apache 2.0.
How Does Apache Storm Compare to Hadoop?
| Attribute | Hadoop | Apache Storm |
|---|---|---|
| Processing model | Batch (start/end boundaries) | Continuous, unbounded streams |
| Latency | Minutes to hours | Sub-second |
| HDFS dependency | Required | Not required |
| Use case fit | Large-scale batch analytics | CEP, real-time alerting |
| State management | External | Limited built-in, needs external |
| License | Apache 2.0 | Apache 2.0 |
Storm’s topology model, where spouts emit data and bolts process it continuously, makes it fundamentally different from Hadoop’s MapReduce. Data enters Storm and transforms through a pipeline of bolts with no defined end. This makes Storm good for CEP use cases like monitoring network anomalies or processing payment events in real time.
When Should You Choose Apache Storm Over Hadoop?
- Storm is the better choice when the system must react to individual events within milliseconds, such as fraud signals or IoT device alerts.
- Storm is preferable when workloads run continuously without scheduled batch windows and results must be emitted as events arrive.
What Are the Limitations of Apache Storm Compared to Hadoop?
- Limited state management: Storm lacks built-in advanced state backends. Teams needing complex stateful aggregations typically add external systems like Redis or Cassandra.
- Storm’s community activity has declined relative to Apache Flink and Spark Streaming, which now offer comparable streaming capabilities with broader ecosystems and active development.
- Storm lacks built-in event-time windowing and advanced features that Flink provides natively, making it less suitable for time-sensitive analytics requiring late-data handling.
Is Amazon Redshift a Good Hadoop Alternative for Structured Data Warehousing?
Amazon Redshift is a strong Hadoop alternative for structured data warehousing on AWS. Its columnar storage and massively parallel processing architecture delivers fast SQL query performance on structured datasets without the operational overhead of maintaining HDFS or YARN.
What Is Amazon Redshift?
Amazon Redshift is a fully managed cloud data warehouse offered by AWS. It was launched in 2013 and uses columnar storage with data compression to optimize analytical queries across structured data.
Redshift integrates with S3, Glue, and AWS Lake Formation. It supports standard SQL and connects to BI tools like Tableau, Looker, and Power BI. The pricing model is instance-based, with a serverless option added in 2022.
How Does Amazon Redshift Compare to Hadoop?
| Attribute | Hadoop | Amazon Redshift |
|---|---|---|
| Storage format | Row-based HDFS | Columnar, compressed |
| Query language | HiveQL | Standard SQL (PostgreSQL-based) |
| Best workload | Batch ETL on unstructured data | Structured data warehouse queries |
| Deployment | Self-managed or managed cluster | Fully managed by Amazon Web Services |
| Scaling | Manual horizontal scaling | Elastic resize, serverless option |
| License | Apache 2.0 | Commercial (AWS) |
Redshift’s columnar compression means it reads only the columns a query needs, unlike Hadoop’s MapReduce which scans entire rows. For reporting workloads with many columns but narrow query projections, this difference is significant. The distributed SQL query engine also enables horizontal vs vertical scaling patterns that Hadoop requires manual node management to achieve.
When Should You Choose Amazon Redshift Over Hadoop?
- Redshift is the better choice when the primary workload is structured SQL analytics on clean, schema-defined datasets rather than raw, unstructured log processing.
- Redshift is preferable when BI teams need concurrent SQL access from multiple analysts without cluster tuning expertise.
- Redshift suits AWS-native organizations that want deep integration with Glue, Lake Formation, and QuickSight without building a custom data stack.
What Are the Limitations of Amazon Redshift Compared to Hadoop?
- AWS-only: Redshift cannot run on GCP or Azure, limiting portability for multi-cloud data strategies.
- Redshift is less suited for semi-structured or unstructured data processing. Hadoop’s ecosystem handles JSON, XML, and raw log files more flexibly through custom MapReduce jobs or Hive.
Is Microsoft Azure HDInsight a Good Hadoop Alternative for Enterprise Big Data on Azure?
Azure HDInsight is a managed Hadoop alternative for enterprises running on Microsoft Azure. It provides fully managed clusters running Apache Hadoop, Spark, Kafka, and HBase natively, integrating with Azure Data Lake Storage and Active Directory for enterprise security.
What Is Microsoft Azure HDInsight?
Azure HDInsight is a fully managed cloud big data service offered by Microsoft Azure. It supports multiple open-source frameworks including Hadoop, Spark, Hive, Storm, Kafka, and HBase without requiring manual cluster configuration.
HDInsight integrates with Azure Active Directory, Azure Monitor, and Azure Data Lake Storage Gen2. It is priced per cluster-hour by node type. The underlying frameworks (Hadoop, Spark) remain Apache 2.0 licensed, while the managed service is commercial.
How Does Azure HDInsight Compare to Hadoop?
| Attribute | Hadoop (self-managed) | Azure HDInsight |
|---|---|---|
| Cluster management | Manual | Fully managed by Microsoft |
| Framework support | Hadoop ecosystem | Hadoop, Spark, Kafka, HBase, Storm |
| Security integration | Kerberos, Ranger manual setup | Azure AD, Enterprise Security Package |
| Storage backend | HDFS | Azure Data Lake Storage Gen2 |
| Cloud dependency | Cloud-agnostic | Azure only |
| License | Apache 2.0 | Commercial (Azure) |
HDInsight’s Enterprise Security Package makes it the most practical option for organizations already using Azure AD for identity management. Hadoop’s native Kerberos setup is notoriously tricky, and HDInsight abstracts most of that complexity while preserving compatibility with existing MapReduce jobs and Hive workloads. This is relevant for teams managing a complex software development process that includes legacy data pipelines.
When Should You Choose Azure HDInsight Over Hadoop?
- HDInsight is the better choice for enterprises already standardized on Microsoft Azure that need managed Hadoop without rebuilding existing pipelines.
- HDInsight is preferable when enterprise security, Active Directory integration, and compliance logging are non-negotiable requirements from day one.
- HDInsight suits organizations migrating from on-premise Hadoop clusters to the cloud while maintaining workload compatibility with minimal code changes.
What Are the Limitations of Azure HDInsight Compared to Hadoop?
- Azure lock-in: HDInsight is Azure-only and cannot be deployed on AWS or GCP. Teams with multi-cloud strategies must evaluate this constraint carefully.
- HDInsight cluster startup times can be slow. For short, ad-hoc jobs, spinning up an HDInsight cluster is often less cost-efficient than using serverless alternatives like Azure Synapse Analytics.
Is Presto (Trino) a Good Hadoop Alternative for Interactive SQL Queries?
Presto (now forked as Trino) is a strong Hadoop alternative for interactive, low-latency SQL queries across distributed data sources. It queries data in-place across HDFS, S3, Cassandra, and relational databases without moving data into a central warehouse, making it the go-to for federated query use cases.
What Is Presto (Trino)?

Presto is an open-source distributed SQL query engine originally developed by Facebook in 2013 and later forked as Trino by its original creators. Both maintain Apache 2.0 licensing.
Trino is maintained by the Trino Software Foundation with backing from major contributors. Presto is maintained by the Presto Foundation under the Linux Foundation. Both support connectors for HDFS, S3, Hive, MySQL, PostgreSQL, Cassandra, and Kafka. The engine is written in Java and runs without HDFS or YARN.
How Does Presto (Trino) Compare to Hadoop?
| Attribute | Hadoop | Trino / Presto |
|---|---|---|
| Query model | Batch MapReduce | Interactive SQL, federated |
| Latency | Minutes to hours | Seconds to sub-minute |
| Data movement | Data in HDFS | Query data in-place, no ingestion |
| Storage dependency | HDFS required | No native storage, connector-based |
| Use case fit | Large batch jobs | Ad-hoc analytics, BI queries |
| License | Apache 2.0 | Apache 2.0 |
The federated query model is what makes Presto/Trino distinctly different from Hadoop. An analyst can write a single SQL statement that joins data from an S3 data lake, a MySQL operational database, and a Cassandra NoSQL store without any ETL pipeline. This eliminates an entire class of data movement work that Hadoop-based architectures typically require. Facebook originally built Presto to run interactive queries on their Hadoop data warehouse, and it proved so effective they deprecated HiveQL for analyst workloads.
When Should You Choose Presto (Trino) Over Hadoop?
- Presto is the better choice when analysts need ad-hoc SQL queries that return results in seconds rather than waiting for MapReduce batch jobs.
- Presto is preferable when data lives across multiple heterogeneous sources and moving it to a central warehouse is impractical or expensive.
- Presto suits organizations with existing Hive metastore setups that want faster interactive query performance without replacing their data lake infrastructure.
What Are the Limitations of Presto (Trino) Compared to Hadoop?
- No native storage: Presto and Trino are query-only engines. They have no file system, no job scheduler, and no built-in fault-tolerant storage. They must be paired with S3, HDFS, or another persistent store.
- For very large batch ETL jobs, Presto’s interactive query model is less efficient than Spark or Hadoop MapReduce, which are optimized for throughput over latency.
- The Presto/Trino fork split created ecosystem fragmentation. Some connectors and features diverge between the two projects, requiring teams to evaluate which branch better fits their existing stack.
What Is Hadoop and Why Do Teams Replace It?
Hadoop is an open-source distributed computing framework built around four core components: HDFS (Hadoop Distributed File System), MapReduce, YARN, and Hadoop Common.
HDFS handles fault-tolerant storage across commodity hardware. MapReduce processes data in parallel by splitting jobs into map and reduce phases. YARN manages cluster resources. Hadoop Common provides the shared utilities that tie them together.
Around 220,000 enterprises globally use Hadoop, with adoption concentrated in banking, government, and retail, according to KITRUM (2025).
The migration pressure comes from three specific architectural limits:
- MapReduce writes intermediate results to disk after every processing step, creating latency that rules out real-time workloads
- Cluster management requires dedicated platform engineering teams for provisioning, patching, and security tuning
- HiveQL lacks the SQL maturity that business analysts and BI tools expect
Hadoop still holds ground in specific scenarios. Long-term archival on commodity hardware costs $10-15/TB per year vs. $240+ for cloud storage. On-premise deployments remain the default for organizations with data sovereignty or compliance constraints.
Hadoop 3.4.2 (August 2025) is the current stable release, introducing enhanced S3A support and conditional writes. The project is maintained but no longer the default starting point for new distributed data infrastructure.
How Do the Top Hadoop Alternatives Compare?
The 10 alternatives covered here split into three clusters. Choosing the wrong cluster wastes migration effort.
| Alternative | Category | Processing model | Best fit |
|---|---|---|---|
| Apache Spark | Open-source engine | Batch + stream + ML | Iterative analytics, ML pipelines |
| Apache Flink | Open-source engine | Stream-first, batch supported | Event-driven, real-time pipelines |
| Apache Storm | Open-source engine | Continuous stream (CEP) | Real-time alerting, event processing |
| Databricks | Managed cloud platform | Unified (Spark + Delta Lake) | Lakehouse, ML, data engineering |
| Google BigQuery | Managed cloud platform | Serverless SQL | Petabyte SQL analytics, GCP-native |
| Snowflake | Managed cloud platform | Separated compute/storage SQL | Multi-cloud data warehousing |
| Amazon EMR | Managed cloud platform | Hadoop/Spark managed cluster | AWS-native big data workloads |
| Azure HDInsight | Managed cloud platform | Managed Hadoop ecosystem | Enterprise Hadoop migration to Azure |
| Amazon Redshift | Managed cloud platform | Columnar SQL warehouse | Structured data warehousing on AWS |
| Trino / Presto | Federated query engine | Interactive SQL, no data movement | Ad-hoc queries across heterogeneous sources |
The decision signal is simple: teams leaving Hadoop for speed should evaluate open-source engines. Teams leaving for cloud migration should evaluate managed platforms. Teams leaving because analysts need SQL access should evaluate federated query engines or columnar warehouses.
38% of companies now run multiple data warehouses simultaneously, according to State of Analytics Engineering 2024. Full replacement is less common than layered adoption.
Open-Source Processing Engines as Hadoop Alternatives
The streaming analytics market was valued at $31.3 billion in 2024 and is projected to reach $99.3 billion by 2030 at a 26% CAGR, according to Virtue Market Research. That trajectory explains why Hadoop’s batch-only model is losing ground to open-source processing frameworks built for continuous data.
Over 20,294 companies globally used Apache Spark as a data analytics tool in 2025, according to 6sense. Flink and Storm fill narrower niches.
Is Apache Spark a Good Hadoop Alternative for Real-Time Data Processing?
Apache Spark is a strong Hadoop alternative for real-time and iterative data processing. Its in-memory computing model is up to 100x faster than Hadoop MapReduce for memory-based operations, and its unified engine covers batch, streaming, ML, and graph workloads without extra tools.
What Spark is: Open-source distributed computing engine, Apache Software Foundation, Apache 2.0 license, first released 2010 at UC Berkeley’s AMPLab, current stable branch Spark 3.x, supports Java/Scala/Python/R.
Spark’s DAG (Directed Acyclic Graph) execution model optimizes entire workflows before execution begins. That contrasts with Hadoop’s linear MapReduce, which processes each step independently and writes to disk between phases.
When Spark fits better than Hadoop:
- ML training loops that pass over the same data 10+ times (Spark’s in-memory caching eliminates repeated disk reads)
- Fraud detection, live dashboards, or IoT event processing requiring sub-second latency
- Teams standardized on Python via PySpark and pandas interop
- Single platform handling batch ETL, real-time analytics, and ML without separate cluster tooling
Key limitations vs. Hadoop: Production Spark clusters require 64-128 GB RAM per node, making hardware costs 30-40% higher than Hadoop’s disk-based nodes. Spark has no native distributed file system and depends on HDFS, Amazon S3, or another external store.
Is Apache Flink a Good Hadoop Alternative for Streaming Pipelines?
Apache Flink delivers true per-record processing with sub-second latency. Where Spark Streaming uses micro-batching to simulate real-time behavior, Flink processes each record as it arrives. That gap matters in credit card fraud detection, where even a 5-second delay is too long.
Netflix uses Flink to power real-time streaming applications at scale. Alibaba runs Flink as the backbone of its real-time data platform, processing trillions of events per day.
Architecture compared to Hadoop:
| Attribute | Hadoop | Apache Flink |
|---|---|---|
| Processing model | Batch (MapReduce) | Stream-first, batch supported |
| Latency | Minutes to hours | Sub-second per-record |
| State management | None built-in | Native, fault-tolerant (RocksDB) |
| Time semantics | Processing time only | Event time, processing time, ingestion time |
Flink is the better choice when the pipeline handles out-of-order events, late-arriving data, or complex windowed aggregations where Hadoop’s batch model cannot apply.
Limitations: Flink’s Python and ML ecosystem lags behind Spark. Batch processing throughput for very large static datasets is efficient but not consistently faster than Spark. Operational setup, especially RocksDB state backend tuning and checkpoint configuration, requires distributed systems expertise.
Is Apache Storm a Good Hadoop Alternative for Complex Event Processing?
Storm is a specialized Hadoop alternative. Not a general one.
It was created by BackType, acquired by Twitter in 2011, and open-sourced under the Apache Software Foundation. Storm processes data through continuously executing topologies, where spouts emit data and bolts transform it in an unbounded stream with no start or end boundary.
Storm vs. Hadoop at a glance:
- No HDFS or YARN dependency (uses ZooKeeper for coordination)
- Sub-second latency for individual event processing
- Designed for CEP: network anomaly detection, payment event processing, real-time alerting
- Does not compete with Hadoop on batch ETL throughput
Storm is the better choice when the system must react to individual events within milliseconds and workloads run continuously without scheduled batch windows. Avoid Storm for use cases requiring complex stateful aggregations or advanced event-time windowing. Both Flink and Spark Streaming now offer comparable streaming capabilities with more active communities and broader ecosystems.
Managed Cloud Platforms as Hadoop Alternatives

Snowflake reached a $3.8 billion revenue run rate in 2024 at 27% YoY growth, while Databricks surpassed $4.8 billion at 55%+ YoY, according to Wing VC and Databricks press releases. Both numbers signal how fast enterprise data infrastructure is shifting away from self-managed Hadoop clusters.
The global data lakehouse market was valued at $11.9 billion in 2024 and is expected to reach $105.9 billion by 2034 at a 25% CAGR, according to Global Market Insights. Databricks, Snowflake, AWS, Microsoft, and Google held 54% of that market in 2024.
Is Databricks a Good Hadoop Alternative for Lakehouse Architectures?
Databricks set a data warehousing performance record on the 100 TB TPC-DS benchmark and reported being 2.7x faster than Snowflake on that test. Over 8,000 customers used Databricks SQL as their data warehouse as of September 2024, according to Databricks.
Core architecture: Databricks runs on Apache Spark with Delta Lake as default storage. Delta Lake adds ACID transactions and schema evolution to object storage. Unity Catalog (added 2023) provides centralized governance across Delta Lake and Apache Iceberg tables. Deployed on AWS, Azure, and GCP. Commercial SaaS, Delta Lake is Apache 2.0.
Choose Databricks over Hadoop when:
- ML training pipelines need to run alongside ETL jobs on the same platform (MLflow, MLlib, AutoML built in)
- Data engineers and data scientists need shared notebooks with version-controlled workflows
- The team is migrating from Hadoop and wants to keep Spark compatibility while gaining managed infrastructure and Delta Lake governance
Limitations: Databricks is a paid platform. Cost scales with compute usage, and large production clusters can become expensive relative to self-managed Hadoop on commodity hardware. Teams relying on Hadoop ecosystem tools like HBase, Pig, or Oozie need to rewrite or replace those workloads during migration.
Is Google BigQuery a Good Hadoop Alternative for SQL Analytics at Scale?
BigQuery holds a 13.48% market share in the cloud data warehousing category (6sense). Its serverless Dremel query engine lets teams query petabyte datasets without cluster provisioning, YARN tuning, or HDFS management.
What BigQuery is: Fully managed, serverless cloud data warehouse by Google Cloud Platform. Columnar storage via Google’s Colossus distributed file system. Supports standard SQL, auto-scales, integrates natively with Looker, Vertex AI, and Google Sheets. Pay-per-query or slot-based pricing. Google Cloud only.
One CTO at a SaaS analytics company reduced nightly batch costs by 10x after switching from Hadoop to BigQuery flex slots, according to StackShare community data.
Limitations vs. Hadoop: BigQuery runs exclusively on Google Cloud. Custom processing logic that Hadoop supports through MapReduce or Spark jobs requires separate Cloud Dataflow pipelines. At high query volumes, slot-based pricing can exceed the fixed cost of a well-tuned on-premise Hadoop cluster.
Is Snowflake a Good Hadoop Alternative for Cloud Data Warehousing?

PeerSpot ranks Snowflake first among cloud data warehousing platforms with an average rating of 8.4. G2 shows Snowflake outperforms Hadoop on ease of use and setup.
The core architectural difference: Snowflake separates compute from storage completely. A Hadoop cluster must scale both dimensions together, wasting resources when storage grows faster than compute or vice versa. Snowflake scales each independently.
Snowflake vs. Hadoop summary:
- Deployment: Multi-cloud SaaS (AWS, Azure, GCP) vs. self-managed on-premise
- Query language: Full ANSI SQL vs. HiveQL (limited)
- Real-time ingestion: Snowpipe for continuous loading vs. not supported natively
- License: Commercial SaaS vs. Apache 2.0 open source
Limitations: Snowflake’s credit-based compute pricing can become expensive for always-on, high-concurrency workloads. Python-based ML pipelines or graph processing require external tools like Spark or Databricks.
Is Amazon EMR a Good Hadoop Alternative for AWS-Native Big Data Workloads?
Amazon EMR manages Hadoop and Spark cluster provisioning, integrates natively with S3, Glue, and Redshift, and supports spot instance pricing that can cut cluster costs 60-80% for fault-tolerant batch workloads.
AWS introduced serverless EMR in 2024, enabling workloads to scale automatically and bill only for actual resource consumption, according to Mordor Intelligence.
EMR vs. self-managed Hadoop:
| Attribute | Hadoop (self-managed) | Amazon EMR |
|---|---|---|
| Cluster management | Manual, requires ops team | Fully managed by Amazon Web Services |
| Storage | HDFS on local disks | EMRFS on Amazon S3 (persistent) |
| Framework support | Hadoop ecosystem | Hadoop, Spark, Flink, Presto, Hive |
| Cost model | Fixed hardware investment | Pay per EC2 hour, spot available |
EMR is the better choice for organizations already on AWS that want managed Hadoop without rewriting existing jobs. Key limitation: EMR is AWS-only. Multi-cloud or data sovereignty requirements that mandate on-premise deployment cannot use EMR. Clusters backed by HDFS (not S3) also lose data on termination.
Is Azure HDInsight a Good Hadoop Alternative for Enterprise Big Data on Azure?
HDInsight is the right Hadoop alternative when enterprise security, Active Directory integration, and compliance logging are non-negotiable requirements from day one.
Hadoop’s native Kerberos setup is notoriously complex to configure. HDInsight abstracts most of that complexity through its Enterprise Security Package, which maps directly to Azure Active Directory for identity management.
Framework support: Hadoop, Spark, Kafka, HBase, Storm, and Hive. All managed by Microsoft Azure. Storage backend is Azure Data Lake Storage Gen2 rather than HDFS.
HDInsight suits enterprises already standardized on Microsoft Azure that need managed Hadoop without rebuilding existing pipelines. Limitation: Azure-only. Cluster startup times can be slow, making serverless alternatives like Azure Synapse Analytics more cost-efficient for short, ad-hoc jobs.
Is Amazon Redshift a Good Hadoop Alternative for Structured Data Warehousing?
Redshift’s columnar storage reads only the columns a query needs. Hadoop MapReduce scans entire rows. For reporting workloads with narrow query projections, this difference is significant in both speed and cost.
Redshift vs. Hadoop: PostgreSQL-compatible SQL vs. HiveQL. Columnar compression vs. HDFS row storage. Elastic resize and serverless option (added 2022) vs. manual horizontal node expansion. AWS-only vs. cloud-agnostic self-managed deployment.
Redshift is the better choice when the primary workload is structured SQL analytics on clean, schema-defined datasets, and BI teams need concurrent query access from multiple analysts. Redshift is less suited for semi-structured or unstructured data processing, where Hadoop’s MapReduce and Hive handle JSON, XML, and raw log files more flexibly.
Federated Query Engines as Hadoop Alternatives
Presto was originally created at Facebook in 2013 to run interactive SQL queries on their 300 PB Hive data warehouse when HiveQL proved too slow for analyst workloads. Facebook open-sourced it in November 2013.
In 2020, Presto’s original creators forked the project due to governance concerns, naming the fork PrestoSQL, later rebranded as Trino in December 2020. The two projects now have separate foundations: Presto Foundation (Meta) and Trino Software Foundation. Both are Apache 2.0 licensed.
Trino powers analytics at scale for Apple, Stripe, Salesforce, Netflix, and LinkedIn, according to Data Engineer Things (2025).
Is Presto (Trino) a Good Hadoop Alternative for Interactive SQL Queries?
The federated model is what separates Presto and Trino from every other alternative on this list. They query data in-place across HDFS, S3, MySQL, Cassandra, and Kafka using a single SQL statement, without any ETL pipeline or data movement.
Presto/Trino return results in seconds vs. Hadoop MapReduce’s minutes-to-hours latency. Amazon Athena, the managed query service on AWS, uses Presto as its engine.
Trino adoption examples:
- Apple: queries large datasets across multiple heterogeneous sources
- Robinhood and DoorDash: detailed use cases at Trino Summit 2021
- Treasure Data: migrated from Presto to Trino in 2024, handling 95% of customer queries within 1 minute
Key limitations vs. Hadoop:
- No native storage: Query-only engines. Must be paired with S3, HDFS, or another persistent store
- Large-scale batch ETL throughput is weaker than Spark or Hadoop MapReduce, which are optimized for throughput over latency
- The Presto/Trino fork split created ecosystem fragmentation, with some connectors and features diverging between projects
How to Choose a Hadoop Alternative for Your Use Case
Most large organizations in 2025 do not pick a single Hadoop replacement. They run Spark or Flink for processing alongside BigQuery, Snowflake, or Redshift for analytics. 38% of companies already use multiple data warehouses simultaneously, per State of Analytics Engineering 2024.
The decision maps to three axes:
| If your priority is… | Best fit alternative(s) | Avoid |
|---|---|---|
| Real-time / streaming | Apache Flink, Apache Storm | Amazon Redshift, Google BigQuery (not built for per-record CEP) |
| ML + batch ETL together | Databricks, Apache Spark | Apache Storm (no ML), Presto (no batch throughput) |
| SQL analytics, no cluster ops | Google BigQuery, Snowflake, Amazon Redshift | Self-managed Apache Spark, Apache Flink |
| AWS-native migration | Amazon EMR, Amazon Redshift | Azure HDInsight, Google BigQuery |
| Cross-source federated queries | Presto, Trino | Snowflake, Amazon Redshift (require data ingestion) |
Migration path matters. Teams with existing HiveQL jobs migrate most easily to Presto/Trino or Amazon EMR, since both preserve HiveQL compatibility. Teams with MapReduce jobs need Spark rewrites.
Infrastructure budget is the second constraint. Commodity hardware with no managed overhead keeps teams on self-managed Spark or Flink. Teams willing to pay for operational simplicity move to serverless options (BigQuery) or managed platforms (Databricks, Snowflake).
Cloud commitment is the third. AWS-first teams choose EMR or Redshift. Azure-first teams choose HDInsight. GCP-first teams choose BigQuery. Multi-cloud or cloud-agnostic teams choose Snowflake or self-managed Spark/Flink on Kubernetes.
The software scalability requirements of your data platform should drive the final decision, not vendor marketing. A team running a large-scale software development process with ML pipelines has different constraints than a BI team running weekly reports.
FAQ on Hadoop Alternatives
What is the best Hadoop alternative in 2025?
Apache Spark is the most widely adopted replacement. It handles batch processing, real-time streaming, and machine learning in one unified engine. For SQL-only workloads, Snowflake or Google BigQuery are stronger fits depending on your cloud provider.
Is Apache Spark a full replacement for Hadoop?
Spark replaces Hadoop’s MapReduce processing layer but not its storage layer. Most teams pair Spark with Amazon S3 or keep HDFS for distributed file storage. It is a processing engine, not a complete distributed computing framework on its own.
What is the best Hadoop alternative for real-time data processing?
Apache Flink is the top choice for true real-time, per-record stream processing. It delivers sub-second latency and native stateful computation. Spark Streaming works for near-real-time use cases where micro-batch processing is acceptable.
What is the difference between Hadoop and Snowflake?
Hadoop is a self-managed, on-premise distributed processing framework. Snowflake is a fully managed cloud data warehouse with separated compute and storage. Snowflake runs SQL queries on structured data. Hadoop handles raw, unstructured batch workloads at lower storage cost.
Is Databricks better than Hadoop?
Databricks outperforms Hadoop for iterative analytics, ML pipelines, and lakehouse architectures. It combines Apache Spark processing with Delta Lake ACID transactions. Hadoop still has a cost advantage for large-scale archival storage on commodity hardware.
Can Google BigQuery replace Hadoop?
BigQuery replaces Hadoop for petabyte-scale SQL analytics without cluster management. It does not replace Hadoop for unstructured data processing or custom MapReduce jobs. Teams locked into Google Cloud benefit most from the serverless architecture and automatic scaling.
What is the easiest Hadoop alternative to migrate to?
Amazon EMR is the lowest-friction migration path. It runs the full Hadoop ecosystem on AWS, including Hive, YARN, and HDFS-compatible storage via EMRFS on S3. Existing MapReduce jobs and HiveQL queries run without rewriting.
Is Presto the same as Trino?
They share the same origin at Facebook but are now separate projects. Trino forked from Presto in 2020 and evolves at a faster pace. Both are open-source federated query engines that run interactive SQL across HDFS, S3, and relational databases without data movement.
What Hadoop alternative works best for machine learning workloads?
Databricks is the strongest option, with MLflow, MLlib, and AutoML built directly into the platform. Apache Spark also supports ML pipelines via MLlib. Hadoop has no native machine learning library and historically required external tools like Apache Mahout.
When should you stick with Hadoop instead of switching?
Hadoop remains the right choice for long-term archival storage on commodity hardware, on-premise deployments with data sovereignty requirements, and legacy systems with significant MapReduce investment. It costs $10-15 per TB per year versus $240+ for equivalent cloud storage.
Conclusion
This conclusion is for an article presenting Hadoop alternatives across every major use case, from open-source stream processing engines to fully managed cloud data platforms.
No single tool wins universally. The right choice depends on your workload type, cloud commitment, and team expertise.
Need iterative analytics or ML pipelines? Apache Spark or Databricks. Need sub-second latency on unbounded event streams? Apache Flink. Need zero cluster management with full ANSI SQL? Snowflake, Google BigQuery, or Amazon Redshift.
Most modern data stacks combine two or three of these tools rather than picking one.
Hadoop still earns its place for large-scale archival storage and legacy on-premise workloads. But for new distributed computing infrastructure, lakehouse architecture and cloud-native platforms are now the default starting point.
Many of his resources are available on various design marketplaces and for free on Codepen.
Over the years, he's worked with a range of clients and contributed to design publications like Design Your Way, Designmodo, WebDesignerDepot, WPDean, Speckyboy, and Slider Revolution among others.
- How to Make a Repository Private in GitHub - July 20, 2026
- How to Set Up Google Play Family Library - July 18, 2026
- How to Run Pytest in PyCharm: A Complete Walkthrough - July 16, 2026


